独学でシステム開発を覚えてきた人にとって、なかなかきちんと学ぶ機会が少ないのが、データベースの「インデックス」です。
目に見えるSQLやデータ型と違って、なかなかイメージを掴みづらいものだと思います。
この記事では、「インデックスとは何か」を、できる限り簡単にお話します。
インデックスを語る上で欠かせない存在「オプティマイザー」さん
さて、データベースには「オプティマイザー」さんという、ちっちゃいおっさんが住んでいます。
このおっさんは、データベースが命令(SQL)を受けた時に、実際にテーブルのデータを探しに行く作業をする人です(※)。
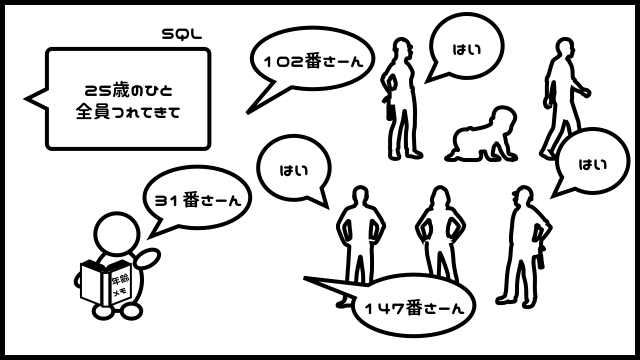
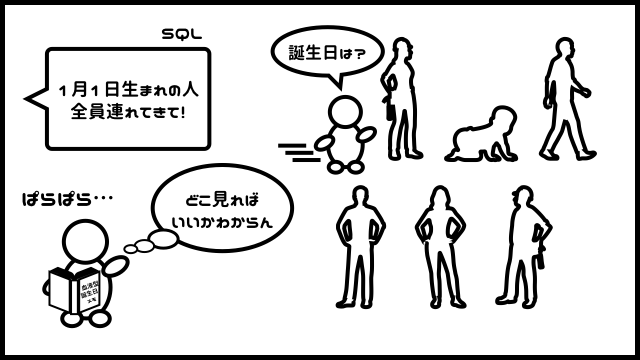
例えば、「1万人の人間が入ったテーブル」に、こんな命令をするとします。
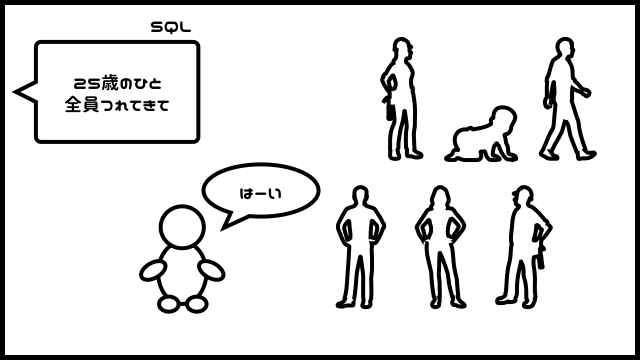
さておっさんはどうするかというと・・・
武器を持たないおっさんは、1万人全員に、年齢を訪ねて回ります。
この探し方を「フルスキャン」といいます。当然、時間がかかります。
あるいは、こんな命令(SQL)を流してみると、

これまた時間がかかります。
人数が多い場合には、そもそも1万人を整列される場所(メモリ)がないとかの問題で、余計に時間がかかったりします。
これでは困りますね。
オプティマイザーさんの秘密兵器「インデックス」
そこで、おっさんにあらかじめこんな指示をしておきます。

この指示を受けたおっさんは、1册のノートを作り始めます。
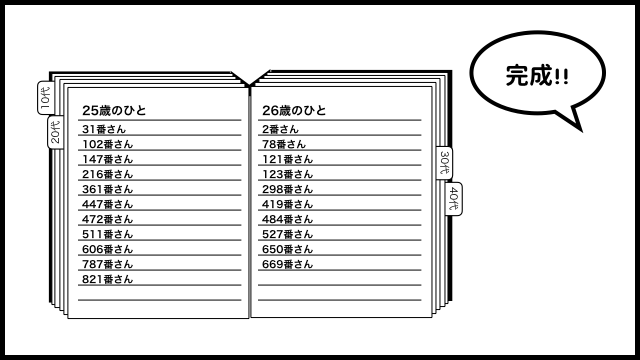
こんな感じのノートです。
ノートには、0歳〜100歳までのページがあり、各ページには、該当者のマイナンバー(ID)が書き連ねられています。
律儀にも、10代、20代、といった見出しシールまで貼られています。
さて、このノートを持っているおっさんに、先程と同じ命令を出すとどうなるでしょうか。

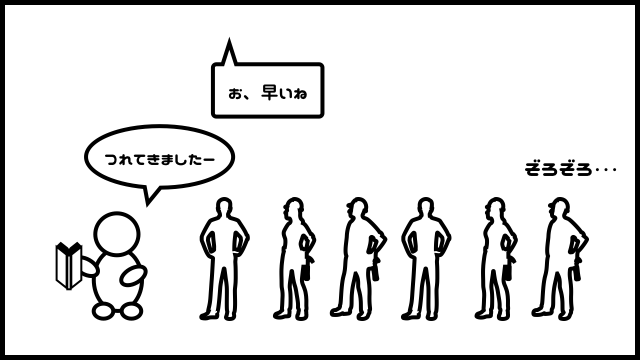
おっさんはまず、「20代」の見出しシールを手繰り、25歳のページを開き、そこに書いてある番号を読み上げていきます。
そして、その番号の人だけを連れてきます。
当然、先程とは比べ物にならないくらい、高速です。
このようなノートを「インデックス」といいます。
そして、先程の「みんなの年齢くらい覚えといて!」という指示を出すことを、「(年齢フィールドに)インデックスを貼る」といいます。
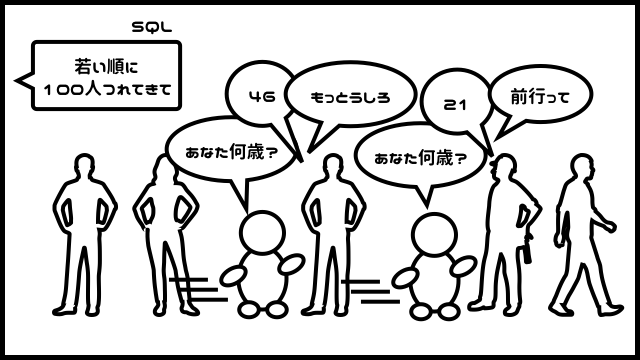
このノートさえあれば、「若い順に100人連れてきて!」も秒殺です。
ノートの頭から順に、100人分の番号を読み上げるだけです。
あるいは、「20代の人全員連れてきて!」でも楽勝です。
見出しシールひとつ分のページを、まるっと読み上げるだけですから。
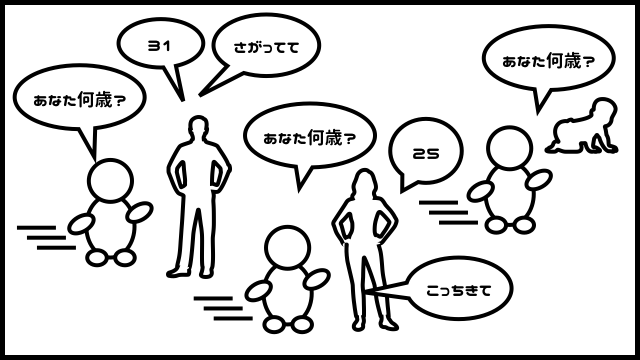
「25歳の女性を全員連れてきて!」だとどうでしょうか。
確かにこのノートだけでは完結できませんが、まず25歳のページを読み上げて、集まった人だけに性別を聞けばよいので、このノートさえない場合よりは、遥かに効率的です。
奥が深い、複合インデックス
さて、こんどはおっさんにこんな命令(SQL)を出してみましょう。

このような場合でも、おっさんにあらかじめ、「年齢と誕生日の組合せは把握しておいて!」と指示を出すだけでいいのです。
指示を受けると、おっさんは文句ひとつ言わず、こんなノートを作り始めます。

このように、2種類以上のフィールドをツリー状に整理して作ったノートを、「複合インデックス」といいます。
このノートを持ったおっさんに、先程と同じ命令を下すと、

秒殺です。
このノートの優れているところは、「AB型の人全員連れてきて!」といった命令(SQL)にも対応できることです。
血液型ごとに大見出しで区切られているので、少しページ数は多くなりますが、まとめて番号を読み上げることができます。
ところが、こんな命令を出してみると・・・
なんとおっさんは、ノートを放り出して、再び全員に誕生日を尋ね始めます。
このおっさん、実は「ノートのページを飛び飛びに見ることが苦手」なのです。
同じ「血液型×誕生日ノート」でも、誕生日が大見出しになっていれば対応できますが、血液型が大見出しになっていると、対応できないのです。
いわゆる「インデックスが利いていない」状態です。
このように、複合インデックスを貼る場合には、「どちらを大見出しにするか」が非常に重要になります。
ダメ、ゼッタイ。インデックス濫用。
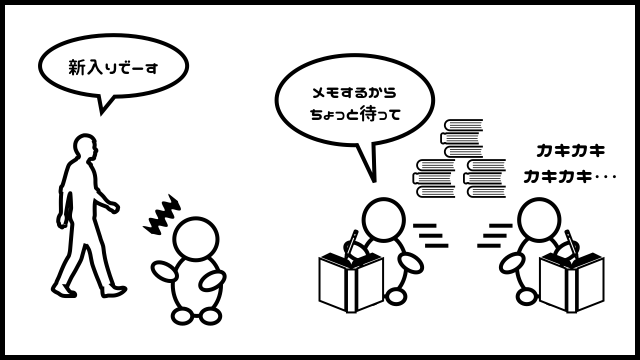
実は、おっさんには、複数のノートを持たせることができます。
それなら、どんな命令(SQL)にでも対応できるように、ありとあらゆる組合せのノート(インデックス)を用意しておけばいいのでは?と思うかもしれません。
ところが、そこにはひとつ落とし穴があります。

ノートが増えすぎると、新しい人が入るたびに、全てのノートに情報を転記する必要が出てきます。
つまり、インデックスが増えすぎると、INSERTやUPDATEが遅くなります。
よく使うSQLのパターンを考え、必要十分なインデックスを用意する必要があるのです。
おしまい。